Why is Server Monitoring Important?
Server monitoring is essential for organisations relying on digital infrastructure. It tracks performance, availability, and health to ensure smooth operations. Without it, businesses face risks like downtime, poor performance, and security threats.
Ensuring Uptime:
Downtime can have severe financial and reputational consequences. Monitoring helps identify potential issues before they escalate, ensuring your servers remain online and accessible.
Optimising Performance:
Proactive monitoring allows you to detect resource bottlenecks and optimise server performance to handle traffic surges or increased workloads.
Enhancing Security:
Monitoring logs and metrics can help detect unauthorised access or suspicious activities, enabling you to respond to potential threats quickly.
Key Benefits of Server Monitoring
Understanding the advantages of server monitoring can help organisations appreciate its value and prioritise its implementation.
Improved Reliability: By continuously tracking server performance, it’s possible to predict and prevent hardware failures or software crashes.
Cost Efficiency: Detecting inefficiencies or underutilised resources helps reduce unnecessary expenses.
Enhanced Troubleshooting: Real-time data and historical insights make it easier to pinpoint the root cause of issues.
Better User Experience: Ensuring high availability and fast response times directly impacts end-user satisfaction.
Compliance and Reporting: For regulated industries, server monitoring assists in meeting compliance requirements and generating audit-ready reports.
Centralised Monitoring: Aggregate logs and metrics from Windows, Linux, and other systems in one platform.
Customisable Dashboards: Visualise performance data in real-time with user-friendly dashboards.
Alerting and Automation: Configure alerts for anomalies and automate responses to common issues.
APM Integration: Monitor application performance alongside server health for a holistic view.
Scalable Solutions: Tailored to meet the needs of businesses of all sizes, from startups to enterprises.
With Logit.io, you gain the tools and insights needed to address challenges proactively and ensure your servers meet the demands of modern infrastructure.
Contents
- Section 1: Getting Started with Server Monitoring
- Section 2: Choosing Your Platform
- Section 3: Logs
- Section 4: Metrics
- Section 5: Application Performance Monitoring (APM)
- Section 6: Introduction to Logit
Section 1: Getting Started with Server Monitoring
What is Server Monitoring?
Server monitoring is the continuous process of observing and analysing a server’s performance, availability, and health. By collecting data from various sources—such as system logs, metrics, and application traces—server monitoring provides insights that help prevent issues and maintain optimal functionality.
Key Components of Server Monitoring
Performance Monitoring
Performance monitoring tracks critical metrics to evaluate the health and efficiency of server operations. Key performance metrics include:
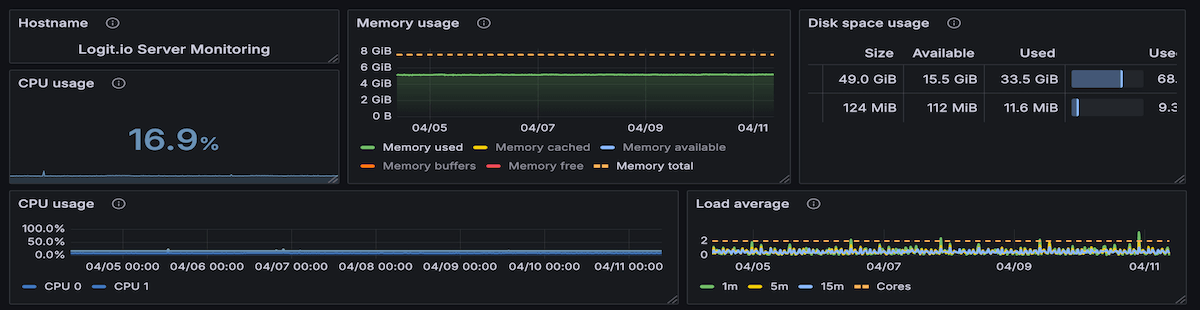
CPU Usage: High CPU utilisation could indicate resource-heavy processes or unoptimised applications. Monitoring this metric ensures the server can handle its workload without overloading, preventing performance degradation or downtime.
Memory Consumption: Memory usage monitoring identifies potential leaks or inadequate allocation, which can cause system crashes or slowdowns. Real-time monitoring ensures that sufficient memory is available for critical applications.
Disk Activity: Monitoring disk I/O, storage utilisation, and read/write speeds prevents issues like disk bottlenecks or insufficient storage, which could disrupt server operations.
Network Performance: By tracking metrics like bandwidth, packet loss, and latency, network performance monitoring ensures servers remain connected to their ecosystems, avoiding communication delays or service interruptions.
Performance monitoring helps maintain optimal server functionality by detecting bottlenecks and inefficiencies early, enabling proactive tuning and scaling.
Availability Monitoring
Availability monitoring ensures servers remain operational and accessible, minimising downtime. This includes:
Uptime Tracking: Monitoring tools continuously check server availability to identify outages or disruptions. This ensures adherence to SLAs and supports customer satisfaction.
Service and Endpoint Checks: Regular tests verify the responsiveness of services hosted on the server, such as websites, APIs, and databases, ensuring seamless access for end-users.
Failover Systems Monitoring: Redundancy mechanisms, like load balancers or backup servers, are monitored to ensure they activate automatically during failures, reducing downtime.
Availability monitoring is crucial for organisations that rely on servers to deliver uninterrupted services and maintain operational continuity.
Error Detection
Error detection involves identifying potential faults or failures within the server environment, such as:
Log Analysis: System, application, and event logs are scanned for warnings, errors, and anomalies that might indicate underlying issues. For example, a spike in error logs could signal an application bug or misconfiguration.
Event Correlation: Detecting patterns across multiple log sources helps pinpoint systemic issues, such as resource conflicts or cascading failures.
Application Traces: Monitoring application workflows and dependencies reveals performance issues or breakdowns in functionality, allowing teams to resolve issues before they escalate.
Error detection minimises the impact of faults by enabling teams to address root causes swiftly and prevent future occurrences.
Security Monitoring
Security monitoring is a cornerstone of server monitoring, protecting systems from unauthorised access and potential breaches. Key aspects include:
Access Monitoring: Authentication logs help track successful and failed login attempts, flagging unusual activity such as brute-force attacks or privilege escalation attempts.
Anomaly Detection: Monitoring unusual patterns, such as unexpected data transfers or configuration changes, highlights potential security breaches or insider threats.
Threat Intelligence Integration: Security monitoring tools often integrate with databases of known vulnerabilities, helping identify potential risks in real time.
Security monitoring safeguards sensitive data, maintains system integrity, and ensures compliance with regulatory standards, such as GDPR or PCI DSS.
Why It Matters
Proactive Problem Solving
Early detection of potential issues, such as rising CPU usage or unusual error rates, allows teams to address problems before they impact end-users. For example, identifying a failing disk drive through performance logs ensures timely replacement, preventing downtime.
Data-Driven Decisions
Comprehensive monitoring data empowers organisations to make informed decisions about infrastructure. For example, if metrics indicate consistently high server load, capacity planning can ensure timely upgrades or scaling to meet demand.
Compliance
Many industries require robust monitoring practices to meet regulatory standards. Monitoring not only helps organisations demonstrate compliance but also provides the logs and audit trails necessary for inspections or legal inquiries.
How It Works
Data Collection
Monitoring tools and agents collect data from server components, including the operating system, applications, network interfaces, and hardware. This data includes metrics, event logs, error messages, and system health indicators, providing a comprehensive view of server activity.
Analysis
The collected data is processed and analysed to identify trends, anomalies, and areas requiring attention. For example, an analysis may reveal a pattern of increasing memory usage over time, indicating a potential memory leak. Advanced tools may use machine learning to forecast issues and provide predictive insights.
Visualisation
Interactive dashboards convert raw data into visual formats, such as graphs, heatmaps, and trend lines. These visualisations allow teams to quickly assess server health and identify outliers. Dashboards can also display real-time metrics, offering immediate insight into the server’s performance and stability.
Alerts
Customisable alerts notify teams of critical events, such as high CPU usage, unauthorised access attempts, or application failures. Alerts can be sent via email, SMS, or integrated with incident response tools like PagerDuty or Slack. These notifications ensure timely responses to issues.
Prerequisites for Monitoring
Logit.io removes all the complexity from Server Monitoring. In order to set up the monitoring here are the key prerequisites:
Ensure the servers have sufficient CPU, memory, and storage capacity to support monitoring agents and data collection tools.
Ensure that necessary ports are open for data transmission to the monitoring platform (e.g., TCP/UDP ports for Logit.io).
Use encrypted connections (e.g., TLS/SSL) to safeguard data during transmission.
Set baseline values and alert thresholds for critical metrics like CPU usage, disk space, and memory.
Install appropriate agents for collecting logs, metrics, and traces. We have written guides to make setting up these agents really straightforward. Here is a list of the agents we recommend depending on whether you require Logs, Metrics, or Traces:
Logs
Logstash: Efficient for ingesting and transforming logs, with compatibility to send data to OpenSearch. To find out more about our Hosted Logstash for more information.
Fluentd: A highly flexible log aggregator that integrates well with OpenSearch. To find out more about Fluentd you can visit here for more information.
Filebeat: A lightweight shipper that collects logs from files and forwards them to OpenSearch. It’s part of the Elastic Beats family but works seamlessly with OpenSearch. To find out more about our Filebeat Integration.
Metrics
Metricbeat: Designed to collect and ship system and application metrics to OpenSearch. To find out more about our metricbeat integration for more information.
Telegraf: A plugin-driven agent for collecting metrics, with support for exporting data to OpenSearch.
Prometheus Exporters: Gather metrics from your servers and services and, with the right setup, send them to OpenSearch. To find out more about Prometheus you can visit our integration for prometheus for more information.
Traces
OpenTelemetry (OTel): The industry standard for collecting distributed traces, compatible with OpenSearch as a backend for trace data storage. To find out more about OpenTelemetry you can visit our otel integration for more information.
Jaeger: An open-source tracing system that integrates with OpenSearch for visualising and analysing distributed traces. To find out more about Jaeger.
By fulfilling these prerequisites, you can streamline the setup process and ensure a seamless transition to proactive server monitoring with Logit.io.
Conclusion
Effective server monitoring combines performance tracking, availability checks, error detection, and security oversight to maintain reliable and efficient server operations. By using Logit.io, organisations can simplify the monitoring process, gain actionable insights, and optimise their server infrastructure for better performance, security, and compliance.
By integrating server monitoring into your operations, you can ensure reliable performance, reduce downtime, and enhance the overall user experience. Logit.io simplifies this process with tools that collect, analyse, and visualise monitoring data efficiently.
Section 2: Choosing Your Platform
This section outlines the key considerations and specific strategies for monitoring Windows and Linux servers.
Monitoring Windows Servers
Windows servers are commonly used in enterprise environments. Monitoring them effectively involves leveraging native tools and third-party integrations. To find out more about monitoring Windows servers you can visit our getting started guide for monitoring windows servers for more information.
Monitoring Linux Servers
Linux servers are widely used for their flexibility and scalability. Monitoring them requires tools tailored to open-source environments. To find out more about monitoring Linux servers you can visit our getting started guide for monitoring linux servers for more information.
Section 3: Logs
Logs are a cornerstone of server monitoring, providing detailed records of events and activities that occur within your systems. Proper log management ensures quick issue resolution, security, and compliance.
What Are Logs?
Logs are structured or unstructured data entries that record events, actions, and statuses within a system. These entries are generated by operating systems, applications, and network devices.
Why Are Logs Important for Server Monitoring?
Troubleshooting Server Issues: Logs act as a detailed record of server activity, making them crucial for identifying and resolving system issues. They allow administrators to trace the sequence of events leading to a server crash, application failure, or network disruption. By examining server logs—such as error logs, event logs, and system logs—teams can pinpoint root causes and take corrective action quickly, minimising downtime.
Monitoring Server Performance: Logs provide continuous insights into server performance metrics, such as CPU utilisation, memory usage, disk I/O, and network activity. By analysing these logs, you can identify trends like resource contention or inefficient processes, enabling you to fine-tune server configurations and optimise performance. Regular log analysis helps detect performance bottlenecks before they affect user experience or critical operations.
Ensuring Server Security: Security-related logs, such as authentication logs, firewall logs, and access logs, are indispensable for monitoring server integrity. These logs help detect suspicious activities, such as unauthorised login attempts, brute-force attacks, or unexpected changes to system files. In server monitoring, leveraging log data enhances your ability to identify and mitigate potential security threats before they escalate.
Compliance and Audit Readiness: Many server environments must comply with industry regulations and standards, such as GDPR, HIPAA, or PCI DSS. Logs provide a verifiable record of server activity, ensuring compliance with these requirements. They can also demonstrate adherence to security protocols and track configuration changes, which is vital for passing audits and avoiding penalties.
Correlating Server Events Across Systems: In complex environments with multiple servers, correlating logs across systems is critical for identifying interdependencies and understanding the broader impact of an issue. For example, logs from a database server might explain a sudden increase in errors on an application server, providing a holistic view of the server ecosystem.
Supporting Server Health and Stability: Logs capture both normal and abnormal server behaviors, which are essential for tracking system health over time. Analysing logs regularly helps detect hardware issues, such as failing disks or overheating CPUs, allowing preemptive action to maintain server stability and prevent failures.
Enhancing Disaster Recovery for Servers: In server monitoring, logs play a critical role in disaster recovery. They provide detailed insights into the events leading up to a failure, helping teams rebuild and restore servers to their intended state. Logs also serve as a reference for validating that recovery efforts were successful and all services are back online.
Facilitating Server Monitoring Automation: With the use of monitoring tools, logs can trigger automated responses to predefined conditions. For example, a surge in error logs could automatically alert administrators, trigger a restart of services, or scale resources to handle increased demand. This integration of logs into automation workflows streamlines server monitoring and response.
By effectively leveraging logs in server monitoring, organisations can achieve improved reliability, optimised performance, and enhanced security for their server infrastructure. To find out more about Logs you can visit our log management for more information.
Section 4: Metrics
Metrics play a critical role in server monitoring, offering quantitative data that reflects the performance, usage, and health of your systems. Effective metric collection and analysis enable organisations to optimise performance, forecast needs, and maintain reliability.
What Are Metrics?
Metrics are numerical data points that measure specific aspects of a system's performance or behavior over time. These measurements are generated by operating systems, applications, and hardware components, providing real-time and historical insights.
Why Are Metrics Important for Server Monitoring?
Performance Monitoring: Metrics allow you to monitor key performance indicators (KPIs) such as CPU usage, memory consumption, and network throughput. This helps ensure systems are running optimally and prevents potential slowdowns.
Capacity Planning: By analysing historical metrics, organisations can predict future resource needs and plan infrastructure upgrades or scaling accordingly.
Anomaly Detection: Metrics help identify unusual patterns, such as sudden spikes in CPU or memory usage, signaling potential issues before they escalate.
System Optimisation: Understanding usage trends through metrics enables fine-tuning of system configurations to improve efficiency and reduce costs.
Compliance and Reporting: Metrics can support audits and ensure adherence to regulatory requirements by providing evidence of system performance and uptime.
To find out more about Metrics you can visit here for more information.
Section 5: Application Performance Monitoring (APM)
APM is a critical component of server monitoring, offering insights into the performance and behavior of applications. Proper implementation of APM ensures seamless user experiences, quick problem resolution, and optimised application performance.
What is APM?
Application Performance Monitoring (APM) involves the tracking and analysis of application metrics and behaviors to ensure they function efficiently and reliably. It provides end-to-end visibility into application performance by monitoring response times, transaction speeds, error rates, and dependencies.
Why is APM Important for Server Monitoring?
Troubleshooting Application Issues: APM tools provide real-time insights into application errors, slow transactions, and resource bottlenecks, enabling quick identification of root causes.
Enhancing User Experience: By monitoring response times and latency, APM ensures that applications deliver smooth and fast user experiences, preventing user dissatisfaction.
Optimising Resource Usage: APM highlights inefficient code, heavy database queries, or overloaded servers, allowing developers to optimise resource utilisation.
Business Insights: APM tools often offer detailed analytics on application usage patterns, which can drive strategic decisions for scaling or enhancing functionality.
Proactive Problem Resolution: With features like anomaly detection and predictive analytics, APM helps address potential issues before they impact end-users.
Compliance and Reliability: APM ensures adherence to service level agreements (SLAs) by providing consistent monitoring and reporting of application uptime and performance metrics.
To find out more about visit our APM monitoring for more information.
Section 6: Introduction to Logit
Logit.io is a comprehensive observability platform that provides fully managed and hosted open-source services, including OpenSearch (formerly ELK), Grafana, and Prometheus. The platform enables users to centralise and analyse logs, metrics, and traces from various sources and this includes simplifying and enhancing server monitoring. By offering robust tools for managing logs, metrics, and application performance data, Logit.io empowers organisations to maintain seamless operations.
Centralised Monitoring: Aggregate logs and metrics from Windows, Linux, and other systems in one platform.
Customisable Dashboards: Visualise performance data in real-time with user-friendly dashboards.
Alerting and Automation: Configure alerts for anomalies and automate responses to common issues.
APM Integration: Monitor application performance alongside server health for a holistic view.
Scalable Solutions: Tailored to meet the needs of businesses of all sizes, from startups to enterprises.
Getting Started with Logit.io
With Logit.io, you gain the tools and insights needed to address challenges proactively and ensure your servers meet the demands of modern infrastructure.
Start monitoring your servers today with Logit.io’s powerful tools - Sign up for a server monitoring free trial or to find out more about how Logit.io can help you monitor your server here for more information.