SQL Server
Ship your SQL Server Metrics via Telegraf to your Logit.io Stack
Follow the steps below to send your observability data to Logit.io
Metrics
Configure Telegraf to ship SQL Server metrics to your Logit.io stacks.
Install Integration
Install Telegraf
This integration allows you to configure a Telegraf agent to send your metrics to Logit.io.
Choose the installation method for your operating system:
When you paste the command below into Powershell it will download the Telegraf zip file.
Once that is complete, press Enter again and the zip file will be extracted into C:\Program Files\InfluxData\telegraf\telegraf-1.34.1.
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.34.1_windows_amd64.zip -UseBasicParsing -OutFile telegraf-1.34.1_windows_amd64.zip
Expand-Archive .\telegraf-1.34.1_windows_amd64.zip -DestinationPath 'C:\Program Files\InfluxData\telegraf'or in Powershell 7 use:
# Download the Telegraf ZIP file
Invoke-WebRequest -Uri "https://dl.influxdata.com/telegraf/releases/telegraf-1.34.1_windows_amd64.zip" `
-OutFile "telegraf-1.34.1_windows_amd64.zip" `
-UseBasicParsing
# Extract the contents of the ZIP file
Expand-Archive -Path ".\telegraf-1.34.1_windows_amd64.zip" `
-DestinationPath "C:\Program Files\InfluxData\telegraf"The default configuration file is location at:
C:\Program Files\InfluxData\telegraf\telegraf.conf
Configure the Telegraf input plugin
The configuration file below is pre-configured to scrape the system metrics from your hosts, add the following code to the configuration file telegraf.conf from the previous step.
# # Read metrics from SQL queries
[[inputs.sql]]
# ## Database Driver
# ## See https://github.com/influxdata/telegraf/blob/master/docs/SQL_DRIVERS_INPUT.md for
# ## a list of supported drivers.
driver = "mysql"
# ## Data source name for connecting
# ## The syntax and supported options depends on selected driver.
dsn = "username:password@mysqlserver:3307/dbname?param=value"
# ## Timeout for any operation
# ## Note that the timeout for queries is per query not per gather.
# # timeout = "5s"
# ## Connection time limits
# ## By default the maximum idle time and maximum lifetime of a connection is unlimited, i.e. the connections
# ## will not be closed automatically. If you specify a positive time, the connections will be closed after
# ## idleing or existing for at least that amount of time, respectively.
# # connection_max_idle_time = "0s"
# # connection_max_life_time = "0s"
# ## Connection count limits
# ## By default the number of open connections is not limited and the number of maximum idle connections
# ## will be inferred from the number of queries specified. If you specify a positive number for any of the
# ## two options, connections will be closed when reaching the specified limit. The number of idle connections
# ## will be clipped to the maximum number of connections limit if any.
# # connection_max_open = 0
# # connection_max_idle = auto
[[inputs.sql.query]]
# ## Query to perform on the server
query="SELECT user,state,latency,score FROM Scoreboard WHERE application > 0"
# ## Alternatively to specifying the query directly you can select a file here containing the SQL query.
# ## Only one of 'query' and 'query_script' can be specified!
# # query_script = "/path/to/sql/script.sql"
#
# ## Name of the measurement
# ## In case both measurement and 'measurement_col' are given, the latter takes precedence.
# # measurement = "sql"
#
# ## Column name containing the name of the measurement
# ## If given, this will take precedence over the 'measurement' setting. In case a query result
# ## does not contain the specified column, we fall-back to the 'measurement' setting.
# # measurement_column = ""
#
# ## Column name containing the time of the measurement
# ## If ommited, the time of the query will be used.
# # time_column = ""
#
# ## Format of the time contained in 'time_col'
# ## The time must be 'unix', 'unix_ms', 'unix_us', 'unix_ns', or a golang time format.
# ## See https://golang.org/pkg/time/#Time.Format for details.
# # time_format = "unix"
#
# ## Column names containing tags
# ## An empty include list will reject all columns and an empty exclude list will not exclude any column.
# ## I.e. by default no columns will be returned as tag and the tags are empty.
# # tag_columns_include = []
# # tag_columns_exclude = []
#
# ## Column names containing fields (explicit types)
# ## Convert the given columns to the corresponding type. Explicit type conversions take precedence over
# ## the automatic (driver-based) conversion below.
# ## NOTE: Columns should not be specified for multiple types or the resulting type is undefined.
# # field_columns_float = []
# # field_columns_int = []
# # field_columns_uint = []
# # field_columns_bool = []
# # field_columns_string = []
#
# ## Column names containing fields (automatic types)
# ## An empty include list is equivalent to '[*]' and all returned columns will be accepted. An empty
# ## exclude list will not exclude any column. I.e. by default all columns will be returned as fields.
# ## NOTE: We rely on the database driver to perform automatic datatype conversion.
# # field_columns_include = []
# # field_columns_exclude = []
### System metrics
[[inputs.disk]]
[[inputs.net]]
[[inputs.mem]]
[[inputs.system]]
[[inputs.cpu]]
percpu = false
totalcpu = true
collect_cpu_time = true
report_active = true
### Output
[[outputs.http]]
url = "https://@metricsUsername:@metricsPassword@@metrics_id-vm.logit.io:@vmAgentPort/api/v1/write"
data_format = "prometheusremotewrite"
[outputs.http.headers]
Content-Type = "application/x-protobuf"
Content-Encoding = "snappy"Replace connection and driver details with the correct details for your SQL database.
Read more about how to configure data scraping and configuration options for SQL Server (opens in a new tab)
Start Telegraf
From the location where Telegraf was installed (C:\Program Files\InfluxData\telegraf\telegraf-1.34.1) run the program
providing the chosen configuration file as a parameter:
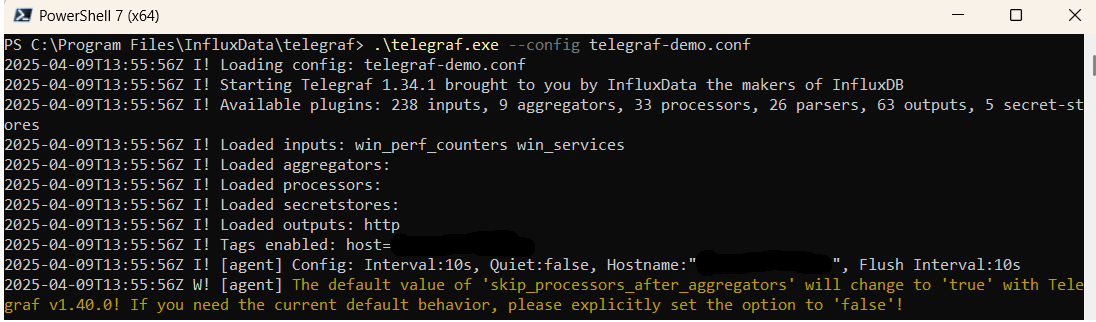
.\telegraf.exe --config telegraf.confOnce Telegraf is running you should see output similar to the following, which confirms the inputs, output and basic configuration the application has been started with:
Launch Grafana to View Your Data
Launch GrafanaHow to diagnose no data in Stack
If you don't see data appearing in your stack after following this integration, take a look at the troubleshooting guide for steps to diagnose and resolve the problem or contact our support team and we'll be happy to assist.
Telegraf SQL Server Overview
To effectively monitor and analyze SQL Server metrics in a distributed environment, organizations require a reliable and efficient metrics management solution. Telegraf, an open-source metrics collection agent, can gather SQL Server metrics from various sources, including operating SQL Server, databases, and other applications.
With a wide range of input plugins, Telegraf enables users to collect metrics from different sources, such as CPU usage, memory usage, network activity, and more. To store and query the collected metrics, organizations can use Prometheus, an open-source monitoring and alerting tool that supports a flexible querying language and graphical visualization of data.
By configuring Telegraf to output metrics in the Prometheus format and using Prometheus to scrape the metrics from the Telegraf server, organizations can ship SQL Server metrics from Telegraf to Prometheus. This process involves setting up Telegraf to collect SQL Server metrics, outputting them in the Prometheus format, configuring Prometheus to scrape the metrics from the Telegraf server, and visualizing the data using Prometheus' flexible querying and graphical visualization capabilities.
Using Telegraf to ship SQL Server metrics to Prometheus is a reliable and efficient metrics management solution for distributed environments. It enables organizations to gain insights into SQL Server performance, optimize their distributed SQL Server, and troubleshoot any issues that arise.
If you need any further assistance with shipping your log data to Logit.io we're here to help you get started. Feel free to get in contact with our support team by sending us a message via live chat & we'll be happy to assist.